As Power BI becomes more prevalent in data analytics and visualization within the enterprise, data security becomes a significant concern. Power BI at its best is deployed to the Power BI service hosted on Microsoft’s Azure platform. Every enterprise should understand the level of security available with their data. Companies who have made the leap to cloud technologies such as AWS, Microsoft Azure, Salesforce, and Microsoft Office 365 should have an understanding of the data compliance and security capabilities of those solutions. However, companies who want to take advantage of Power BI but have just started their cloud journey or are cloud adverse need to know the nuances of Power BI and security.
As Power BI becomes more prevalent in data analytics and visualization within the enterprise, data security becomes a significant concern. Power BI at its best is deployed to the Power BI service hosted on Microsoft’s Azure platform. Every enterprise should understand the level of security available with their data. Companies who have made the leap to cloud technologies such as AWS, Microsoft Azure, Salesforce, and Microsoft Office 365 should have an understanding of the data compliance and security capabilities of those solutions. However, companies who want to take advantage of Power BI but have just started their cloud journey or are cloud adverse need to know the nuances of Power BI and security.
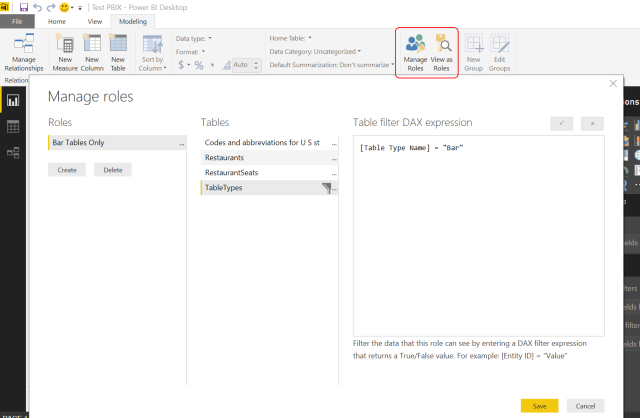
I have been involved with data and cloud security questions a lot of the past few years. With Power BI’s rise in significance, I have had to answer more specific questions about the service. In order to provide proper guidance and not have a reference for myself, I am putting together a short series of posts on various data security items in Power BI. The topics included enterprise gateway, privacy levels, data classification, and compliance. The focus of these articles are related to using the Power BI service as this is the cloud implementation of Power BI. The desktop has setting which impact deployment of assets, but is not the focus of this series.
The Power BI service is updated frequently. These articles were created based on the Power BI implementation in early April 2017. You may find improvements and changes that impact your experience that are based on newer releases. Feel free to add comments to highlight changes.
Power BI Collaboration Basics
The focus of this post is on Power BI collaboration through sharing data using a variety of options in Power BI. While Power BI Desktop is a great tool for building datasets and reports, the real goal of a good BI solution is to share the information and analysis with the correct people in the organization who will be able to make decisions based on it. The Power BI service (https://app.powerbi.com) is the best way to do this.
First, the service requires a work or school based login, it does not work with a Microsoft, Google, Yahoo, or similar accounts. This is the beginning of the walls to protect your data. In most cases you will only be able to share data within your organization. However, there are methods to share dashboards publically. We will discuss those here and show how to turn off or regulate those features within Power BI and Office 365.
Power BI is built with Azure Active Directory (AAD) and customers who have or are in the process of implementing Office 365 are in the best position to establish proper security protocols to manage access to the Power BI service.
Power BI Dashboard Sharing
Power BI sharing can only be done on the service with dashboards. It does not work with reports or datasets and cannot be shared from Power BI Desktop. Initially, I viewed this a not a great option, but the reality is it is the best way to share content in a read only mode. A shared dashboard allows the users to interact with the data and view the underlying reports as part of the solution. This could be a good option when you want to share an executive dashboard with a security group or distribution list within your organization.

Even though the dialog shows email addresses to enter, security groups and distribution lists can also be added here keeping the AAD security model intact. Shared dashboards are marked with a distinct icon:

Dashboards can be shared with free Power BI users within the organization. However, they will not be able to view any dashboards which use Power BI Pro features including workgroups, direct query, live connection, and other Pro based features. It is recommended that all users within an organization have a Pro account at this time.
Managing Share Capabilities within Power BI’s Admin Portal
As one can imagine, when the share dashboard capability was released there were reasonable concerns regarding sharing content outside the organization. When using an email address outside of the domain, users get warned they are sharing content outside of the organization.

This is definitely a significant security risk. We recommend that this feature be disabled. Be aware that it is enabled by default (this may change for newer subscriptions, but most existing subscriptions have this feature on). You can deactivate this option in the Admin Portal – Tenant Settings – Export and sharing Settings as shown below.

If you have some groups who should have permission to share outside the organization you can specify which groups have those permissions. This may be the case where you have a business to business arrangement where sharing a specific dashboard will improve your ability to communicate with the targeted organization.
If you have no compelling reason to share content outside your organization, this feature should be disabled!
Power BI Workspaces
Another way to compartmentalize or secure data is using Workspaces within Power BI. Every user, including free users, have access to My Workspace which is the default location for deploying Power BI and other BI assets. However, you also have the option to create additional workspaces as deployment targets. These Group Workspaces usually have functional and security separation associated with them.
 Here are the key characteristics of a group:
Here are the key characteristics of a group:
- Group membership is individual users. Power BI Groups do not currently support security groups or distribution lists for membership.
- Private vs. Public
- Private groups limit access to members of groups.
- Public groups work like a folder within Power BI and can be used to separate content but are not security restricted.
- You can set the group to “read only” by setting the “Members can only view Power BI content” option.
- This option disables editing on deployed reports and dashboards by members
- Admin users within the group can edit reports and dashboards
- The dataset area is not visible to members, only admins, which prevents creating new reports
With the current limitation around group membership (as of April 2017), I recommend using groups primarily as folders. As this situation improves, they will have more value as security groups as well. However, with the inability to manage these groups with AAD security groups, management will likely be prohibitive. It is likely that users will create groups to provide limited visibility with sharing, but this will create Office 365 groups to manage into the future.
Organizational Content Packs
Another method of sharing content is with organization content packs. Content packs allow the targeted users or groups to pick up the pack and use it in their workspace as needed. They can create copies of the content to use in their own dashboards and to create custom reports on the data. The data access and refresh are determined by the content pack creator. This is a way to not manage workspaces but still make content available to other users. Content packs can be made available to the entire organization, security groups, or distribution lists. Once a user gets the content pack, changes made by the owner can be updated to them as they occur.
You can limit who has permissions to publish content for the entire organization in the Admin Portal – Tenant Settings under the Content Pack Settings header. Users can continue to publish content to specific groups, but will no longer have the “My entire organization” option for publishing.
Publish to Web
Only one option counts here – disable this feature if you don’t want have a reason to display data on the internet!
My recommendation is that if you have a public facing version of your dashboards that do not any security at all, create a new subscription to manage this experience. You can disable this feature in the Admin Portal – Tenant Settings as shown below. All existing Power BI tenants have this enabled by default. You should disable this feature for your primary, internal Power BI implementations.

Exporting Data and Printing Dashboards and Reports
Depending on the needs of your organization, you may need to restrict settings which allow data to be exported or printed. You have the ability to disable or enable exporting data from tiles or visualizations, exporting reports as PowerPoint presentations, and printing dashboards and reports for the entire organization or specific security groups. Both of these features have been highly requested and caution should be taken when disabling them. You can adjust these setting in the Admin portal under Tenant settings.
The Missing “Read Only” User
As you can see from the options to share or create workspaces there are methods which allow you to distribute content in read only fashion. However, in order to properly apply security and other features within Power BI, all of your enterprise users should be Power BI Pro users. Power BI Pro users still have a number of permissions that can cause issues within organizations including the ability to publish and share content from their workspace. Until Microsoft establishes a “read only” user setting or subscriber, organizations will need to manage content with the options noted above and determine the risk. In most cases, the risk is no more an issue than allowing users to use Microsoft Excel or Tableau. However, know your plan and be mindful of the updates from the Power BI team which will expand our ability to manage users.
References
Create a Group in Power BI
Sharing Your Dashboard