

![]() Cosmos DB is one of the fastest growing Azure services in 2018. As its popularity grows, data professionals are faced with a changing reality in the world of data. Data is no longer contained in relational databases as general rule. We saw the start of this with Hadoop data storage, but no one ever referred to Hadoop as a database. Sure Hive and other Hadoop based technologies made the data look like a database, but we (data professionals) were able to keep our distance. What’s changed?
Cosmos DB is one of the fastest growing Azure services in 2018. As its popularity grows, data professionals are faced with a changing reality in the world of data. Data is no longer contained in relational databases as general rule. We saw the start of this with Hadoop data storage, but no one ever referred to Hadoop as a database. Sure Hive and other Hadoop based technologies made the data look like a database, but we (data professionals) were able to keep our distance. What’s changed?
The Cloud, Data, and Databases
As cloud reaches more and more businesses, traditional data stores are being reconsidered. We now have data stored in Azure – Azure Data Lake, Azure Storage, Azure Database Services (SQL, PostgreSQL, MySQL), Azure Data Warehouse, and now Cosmos DB. Cosmos DB is the globalized version of Azure Document DB (more about that later). If we are to grow our skillset and careers to a cloud data professional, we need to know more about other ways the data is stored and used. I want to summarize some things that we need to be aware of about Cosmos DB. If your business uses it or plans to and you are a data pro, you will need to know this.
Introducing Cosmos DB
Azure Cosmos DB is Microsoft’s globally distributed, multi-model database.

Source: https://docs.microsoft.com/en-us/azure/cosmos-db/introduction
I will break down key components of Cosmos DB with a data professional in mind. There are a lot of aspects of Cosmos DB that make it very cool, but you will want to understand this when you get the call to fix the database.
Multi-model Database Service
Currently Cosmos DB supports four database models. This is like having for different database servers in one. I liken it to having SQL Server Database Engine and SQL Server Analysis Services using the same underlying engine and it only “looks different.” Cosmos DB refers to these as APIs. The API is chosen when the database is created. This optimizes the portal and database for use with that API. Other APIs can be used to query the data, but it is not optimal. Here are the four models supported and the APIs that support them.

- Key Value Pair: This is exactly as it sounds. The API is implemented with the Azure Table Storage APIs.
- Wide Column or Column Family: This stores data similar to relational, but there is no row consistency (each row can look different). Cosmos DB uses the Cassandra API to support this model. (For more information on Cassandra click here.)
- Documents: This model is based on JSON document storage. Cosmos DB currently supports two APIs for this model: SQL which is the Document DB API and Mongo DB. These are the most common models used in Cosmos DB today. Document DB is the “parent” to Cosmos DB which was rebranded.
- Graph: Graph databases are used to map relationships in data and were made popular with Facebook for instance. Microsoft uses the open source Gremlin API to support the Graph Database Model.
None of these databases are traditional row/column stores. They are all variations of NoSQL databases.
Turnkey Global Distribution
This is a key attribute for Cosmos DB. Cosmos DB can be easily distributed around the world. Click the data center you want to replicate to and Cosmos DB takes care of the rest. Cosmos DB uses a single write node and multiple read nodes. However, because Cosmos DB was built with global distribution in mind, you can easily and safely move the write node as well. This allows you to “chase the sun” and keep write operations happening “locally”.
Data Consistency
Data consistency is a primary concern of any data professional. The following tables compare Cosmos DB Consistency Levels with SQL Server Isolation Levels. These are not a one for one match, but demonstrate the different concerns between the systems.
Cosmos DB |
SQL Server |
||||
|---|---|---|---|---|---|
| Consistency Level | Guarantees | Isolation Level | Dirty Read | Non- repeatable Read | Phantom |
| Strong | Reads are guaranteed to return the most recent version of an item. | Serializable | No | No | No |
| Bounded Staleness | Consistent Prefix or read order. Reads lag behind writes by prefixes (K versions) or time (t) interval. | Snapshot | No | No | No |
| Session | Consistent Prefix. Monotonic reads, monotonic writes, read-your-writes, write-follows-reads. | Repeatable Read | No | No | Yes |
| Consistent Prefix | Updates returned are some prefix of all the updates, with no gaps. Reads are not read out of order. | Read Committed | No | Yes | Yes |
| Eventual | Out of order reads. | Read Uncommitted | Yes | Yes | Yes |
As you can see, there are some similarities. These options are important to understand. In the Cosmos DB, the more consistent you need the data, the higher the latency in the distributed data. As a result, most Cosmos DB solutions usually start with Session Consistency as this gives a good, consistent user experience while reducing latency in the read replicas.
Throughput
I am not going to dig into this much. But you need to understand that Request Units (RU) are used to guarantee throughput in Cosmos DB. As a baseline, Microsoft recommends thinking that a 1 KB JSON file will require 1 RU. The capacity is reserved for each second. You will pay for what you reserve, not what you use. If you exceed capacity in a second your request will be throttled. RUs are provisioned by region and can vary by region as a result. But they are not shared between regions. This will require you to understand usage patterns in each region you have a replica.
Scaling and Partitions
Within Cosmos DB, partitions are used to distribute your data for optimal read and write operations. It is recommended to create a granular key with highly distinct values. The partitions are managed for you. Cosmos DB will split or merge partitions to keep the data properly distributed. Keep in mind your key needs to support distributed writes and distributed reads.
Indexing
By default, everything is indexed. It is possible to use index policies to influence the index operations. Index policies are modified for storage, write performance, and read or query performance. You need to understand your data very well to make these adjustments. You can include or exclude documents or paths, configure the index type, and configure the index update mode. You do not have the same level of flexibility in indexes found in traditional relational database solutions.
Security
Cosmos DB is an Azure data storage solution which means that the data at rest is encrypted by default and data is encrypted in transit. If you need RBAC, Azure Active Directory (AAD) is supported in Cosmos DB.
SLAs
I think that the SLAs Microsoft provides with Cosmos DB are a key differentiator for them. Here is the short summary of guarantees Microsoft provides:
- Latency: 99.99% of P99 Latency Attainment (based on hours over the guarantee)
- Reads under 10 ms
- Writes under 15 ms
- Availability
- All up – 99.99% by month
- Read – 99.999% by month
- Throughput – 99.99% based on reserved RUs (number of failures to meet reserved amount)
- Consistency – 99.99% based on setting
These are financially backed SLAs from Microsoft. Imagine you providing these SLAs for your databases. This is very impressive.
Wrap Up
For more information, check out Microsoft’s online documentation on Cosmos DB.
I presented this material at the April 2018 PASS MN User Group Meeting. The presentation can be found here.


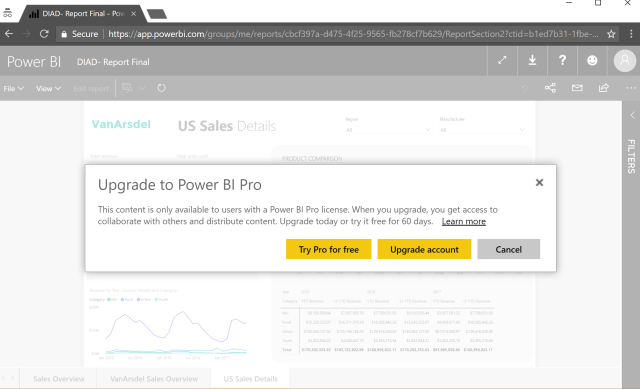
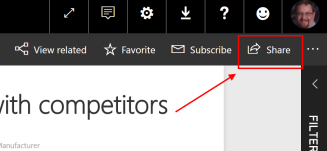
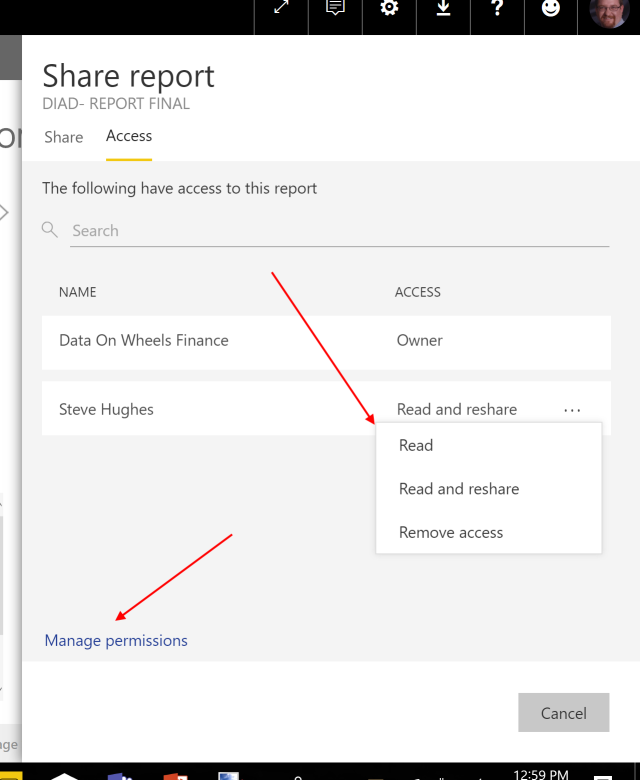
 Time to click the report link. This opens a series of dialogs which determine how much you have access. It is important to note that this is all made possible with Azure B2B. More about that in a moment. Let’s trace the story through. The link opens the following page.
Time to click the report link. This opens a series of dialogs which determine how much you have access. It is important to note that this is all made possible with Azure B2B. More about that in a moment. Let’s trace the story through. The link opens the following page.








 Here are the key characteristics of a group:
Here are the key characteristics of a group:

