This is a reprint with some revisions of a series I originally published on LessThanDot. You can find the links to the original blogs on my Series page.
 In the final installment of my series on SQL window functions, we will explore using analytic functions. Analytic functions were introduced in SQL Server 2012 with the expansion of the OVER clause capabilities. Analytic functions fall in to two primary categories: values at a position and percentiles. Four of the functions, LAG, LEAD, FIRST_VALUE and LAST_VALUE find a row in the partition and returns the desired value from that row. CUME_DIST and PERCENT_RANK break the partition into percentiles and return a rank value for each row. PERCENTILE_CONT and PERCENTILE_DISC a value at the requested percentile in the function for each row. All of the functions and examples in this blog will only work with SQL Server 2012.
In the final installment of my series on SQL window functions, we will explore using analytic functions. Analytic functions were introduced in SQL Server 2012 with the expansion of the OVER clause capabilities. Analytic functions fall in to two primary categories: values at a position and percentiles. Four of the functions, LAG, LEAD, FIRST_VALUE and LAST_VALUE find a row in the partition and returns the desired value from that row. CUME_DIST and PERCENT_RANK break the partition into percentiles and return a rank value for each row. PERCENTILE_CONT and PERCENTILE_DISC a value at the requested percentile in the function for each row. All of the functions and examples in this blog will only work with SQL Server 2012.
Once again, the following CTE will be used as the query in all examples throughout the post:
with CTEOrders as
(select cast(1 as int) as OrderID, cast(‘3/1/2012’ as date) as OrderDate, cast(10.00 as money) as OrderAmt, ‘Joe’ as CustomerName
union select 2, ‘3/1/2012’, 11.00, ‘Sam’
union select 3, ‘3/2/2012’, 10.00, ‘Beth’
union select 4, ‘3/2/2012’, 15.00, ‘Joe’
union select 5, ‘3/2/2012’, 17.00, ‘Sam’
union select 6, ‘3/3/2012’, 12.00, ‘Joe’
union select 7, ‘3/4/2012’, 10.00, ‘Beth’
union select 8, ‘3/4/2012’, 18.00, ‘Sam’
union select 9, ‘3/4/2012’, 12.00, ‘Joe’
union select 10, ‘3/4/2012’, 11.00, ‘Beth’
union select 11, ‘3/5/2012’, 14.00, ‘Sam’
union select 12, ‘3/6/2012’, 17.00, ‘Beth’
union select 13, ‘3/6/2012’, 19.00, ‘Joe’
union select 14, ‘3/7/2012’, 13.00, ‘Beth’
union select 15, ‘3/7/2012’, 16.00, ‘Sam’
)
select OrderID
,OrderDate
,OrderAmt
,CustomerName
from CTEOrders;
Position Value Functions: LAG, LEAD, FIRST_VALUE, LAST_VALUE
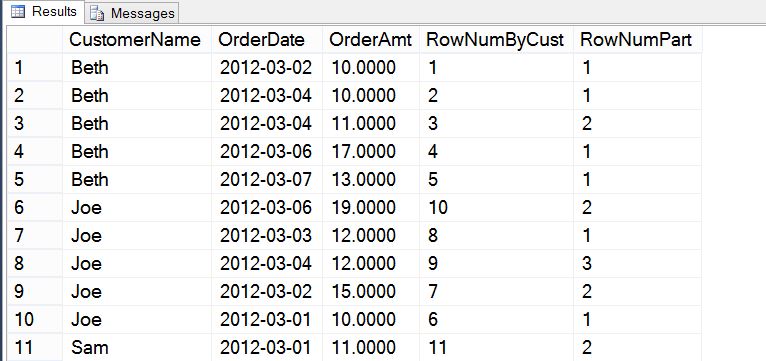
Who has not needed to use values from other rows in the current row for a report or other query? A prime example is needing to know what the last order value was to calculate growth or just show the difference in the results. This has never been easy in SQL Server until now. All of these functions require the use of the OVER clause and the ORDER BY clause. They all use the current row within the partition to find the row at the desired position.
The LAG and LEAD functions allow you to specify the offset or how many rows to look forward or backward and they support a default value in cases where the value returned would be null. These functions do not support the use of ROWS or RANGE in the OVER clause. The FIRST_VALUE and LAST_VALUE allow you to further define the partition using ROWS or RANGE if desired.
The following example illustrates all of the functions with various variations on the parameters and settings.
select OrderID
,OrderDate
,OrderAmt
,CustomerName
,LAG(OrderAmt) OVER (PARTITION BY CustomerName ORDER BY OrderID) as PrevOrdAmt
,LEAD(OrderAmt, 2) OVER (PARTITION BY CustomerName ORDER BY OrderID) as NextTwoOrdAmt
,LEAD(OrderDate, 2, ‘9999-12-31’) OVER (PARTITION BY CustomerName ORDER BY OrderID) as NextTwoOrdDtNoNull
,FIRST_VALUE(OrderDate) OVER (ORDER BY OrderID) as FirstOrdDt
,LAST_VALUE(CustomerName) OVER (PARTITION BY OrderDate ORDER BY OrderID) as LastCustToOrdByDay
from CTEOrders
Results (with shortened column names):
| ID | OrderDate | Amt | Cust | PrevOrdAmt | NextTwoAmt | NextTwoDt | FirstOrd | LastCust |
| 1 | 3/1/2012 | 10 | Joe | NULL | 12 | 3/3/2012 | 3/1/2012 | Joe |
| 2 | 3/1/2012 | 11 | Sam | NULL | 18 | 3/4/2012 | 3/1/2012 | Sam |
| 3 | 3/2/2012 | 10 | Beth | NULL | 11 | 3/4/2012 | 3/1/2012 | Beth |
| 4 | 3/2/2012 | 15 | Joe | 10 | 12 | 3/4/2012 | 3/1/2012 | Joe |
| 5 | 3/2/2012 | 17 | Sam | 11 | 14 | 3/5/2012 | 3/1/2012 | Sam |
| 6 | 3/3/2012 | 12 | Joe | 15 | 19 | 3/6/2012 | 3/1/2012 | Joe |
| 7 | 3/4/2012 | 10 | Beth | 10 | 17 | 3/6/2012 | 3/1/2012 | Beth |
| 8 | 3/4/2012 | 18 | Sam | 17 | 16 | 3/7/2012 | 3/1/2012 | Sam |
| 9 | 3/4/2012 | 12 | Joe | 12 | NULL | 12/31/9999 | 3/1/2012 | Joe |
| 10 | 3/4/2012 | 11 | Beth | 10 | 13 | 3/7/2012 | 3/1/2012 | Beth |
| 11 | 3/5/2012 | 14 | Sam | 18 | NULL | 12/31/9999 | 3/1/2012 | Sam |
| 12 | 3/6/2012 | 17 | Beth | 11 | NULL | 12/31/9999 | 3/1/2012 | Beth |
| 13 | 3/6/2012 | 19 | Joe | 12 | NULL | 12/31/9999 | 3/1/2012 | Joe |
| 14 | 3/7/2012 | 13 | Beth | 17 | NULL | 12/31/9999 | 3/1/2012 | Beth |
| 15 | 3/7/2012 | 16 | Sam | 14 | NULL | 12/31/9999 | 3/1/2012 | Sam |
If you really like subselects, you can also mix in some subselects and have a very creative SQL statement. The following statement uses LAG and a subselect to find the first value in a partition. I am showing this to illustrate some more of the capabilities of the function in case you have a solution that requires this level of complexity.
select OrderID
,OrderDate
,OrderAmt
,CustomerName
,LAG(OrderAmt, (
select count(*)-1
from CTEOrders c
where c.CustomerName = CTEOrders.CustomerName
and c.OrderID <= CTEOrders.OrderID), 0)
OVER (PARTITION BY CustomerName ORDER BY OrderDate, OrderID) as FirstOrderAmt
FROM CTEOrders
Percentile Functions: CUME_DIST, PERCENT_RANK, PERCENTILE_CONT, PERCENTILE_DISC
As I wrap up my discussion on window functions, the percentile based functions were the functions I knew the least about. While I have already used the position value functions above, I have not yet needed to use the percentiles. So, that meant I had to work with them for a while so I could share their usage and have some samples for you to use.
The key differences in the four function have to do with ranks and values. CUME_DIST and PERCENT_RANK return a ranking value while PERCENTILE_CONT and PERCENTILE_DISC return data values.
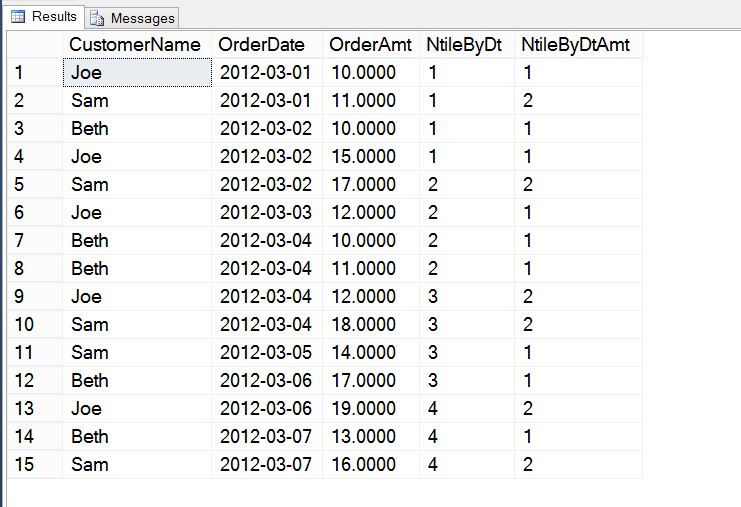
CUME_DIST returns a value that is greater than zero and lest than or equal to one (>0 and <=1) and represents the percentage group that the value falls into based on the order specified. PERCENT_RANK returns a value between zero and one as well (>= 0 and <=1). However, in PERCENT_RANK the first group is always represented as 0 whereas in CUME_DIST it represents the percentage of the group. Both functions return the last percent group as 1. In both cases, as the ranking percentages move from lowest to highest, each group’s percent value includes all of the earlier values in the calculation as well.
The following statement shows both of the functions using the default partition to determine the rankings of order amounts within our dataset.
select OrderID
,OrderDate
,OrderAmt
,CustomerName
,CUME_DIST() OVER (ORDER BY OrderAmt) CumDist
,PERCENT_RANK() OVER (ORDER BY OrderAmt) PctRank
FROM CTEOrders
Results:
| OrderID | OrderDate | OrderAmt | CustomerName | CumDist | PctRank |
| 1 | 3/1/2012 | 10 | Joe | 0.2 | 0 |
| 3 | 3/2/2012 | 10 | Beth | 0.2 | 0 |
| 7 | 3/4/2012 | 10 | Beth | 0.2 | 0 |
| 2 | 3/1/2012 | 11 | Sam | 0.33333333 | 0.214285714 |
| 10 | 3/4/2012 | 11 | Beth | 0.33333333 | 0.214285714 |
| 6 | 3/3/2012 | 12 | Joe | 0.46666667 | 0.357142857 |
| 9 | 3/4/2012 | 12 | Joe | 0.46666667 | 0.357142857 |
| 14 | 3/7/2012 | 13 | Beth | 0.53333333 | 0.5 |
| 11 | 3/5/2012 | 14 | Sam | 0.6 | 0.571428571 |
| 4 | 3/2/2012 | 15 | Joe | 0.66666667 | 0.642857143 |
| 15 | 3/7/2012 | 16 | Sam | 0.73333333 | 0.714285714 |
| 5 | 3/2/2012 | 17 | Sam | 0.86666667 | 0.785714286 |
| 12 | 3/6/2012 | 17 | Beth | 0.86666667 | 0.785714286 |
| 8 | 3/4/2012 | 18 | Sam | 0.93333333 | 0.928571429 |
| 13 | 3/6/2012 | 19 | Joe | 1 | 1 |
The last two functions, PERCENTILE_CONT and PERCENTILE_DISC, return the value at the percentile requested. PERCENTILE_CONT will return the true percentile value whether it exists in the data or not. For instance, if the percentile group has the values 10 and 20, it will return 15. If PERCENTILE_DISC, is applied to the same group it will return 10. It will return the smallest value in the percentile group, which in this case is 10. Both functions ignore NULL values and do not use the ORDER BY, ROWS, or RANGE clauses with the PARTITION BY clause. Instead, WITHIN GROUP is introduced which must contain a numeric data type and ORDER BY clause. Only one column can be specified here. Both functions need a percentile value which can be between 0.0 and 1.0.
The following script illustrates a couple of variations. The first two functions return the median of the default partition. Then next two return the median value for each day. Finally, the last two functions return the low and high values within the partition. The values segmented by the date partition highlight the key difference between the two functions.
select OrderID as ID
,OrderDate as ODt
,OrderAmt as OAmt
,CustomerName as CName
,PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY OrderAmt) OVER() PerCont05
,PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY OrderAmt) OVER() PerDisc05
,PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY OrderAmt) OVER(PARTITION BY OrderDate) PerContDt
,PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY OrderAmt) OVER(PARTITION BY OrderDate) PerDiscDt
,PERCENTILE_CONT(0) WITHIN GROUP (ORDER BY OrderAmt) OVER() PerCont0
FROM CTEOrders
Results
| ID | ODt | OAmt | CName | PerCont05 | PerDisc05 | PerContDt | PerDiscDt | PerCont0 |
| 1 | 3/1/2012 | 10 | Joe | 13 | 13.00 | 10.5 | 10.00 | 10 |
| 2 | 3/1/2012 | 11 | Sam | 13 | 13.00 | 10.5 | 10.00 | 10 |
| 3 | 3/2/2012 | 10 | Beth | 13 | 13.00 | 15.0 | 15.00 | 10 |
| 4 | 3/2/2012 | 15 | Joe | 13 | 13.00 | 15.0 | 15.00 | 10 |
| 5 | 3/2/2012 | 17 | Sam | 13 | 13.00 | 15.0 | 15.00 | 10 |
| 6 | 3/3/2012 | 12 | Joe | 13 | 13.00 | 12.0 | 12.00 | 10 |
| 7 | 3/4/2012 | 10 | Beth | 13 | 13.00 | 11.5 | 11.00 | 10 |
| 10 | 3/4/2012 | 11 | Beth | 13 | 13.00 | 11.5 | 11.00 | 10 |
| 9 | 3/4/2012 | 12 | Joe | 13 | 13.00 | 11.5 | 11.00 | 10 |
| 8 | 3/4/2012 | 18 | Sam | 13 | 13.00 | 11.5 | 11.00 | 10 |
| 11 | 3/5/2012 | 14 | Sam | 13 | 13.00 | 14.0 | 14.00 | 10 |
| 12 | 3/6/2012 | 17 | Beth | 13 | 13.00 | 18.0 | 17.00 | 10 |
| 13 | 3/6/2012 | 19 | Joe | 13 | 13.00 | 18.0 | 17.00 | 10 |
| 14 | 3/7/2012 | 13 | Beth | 13 | 13.00 | 14.5 | 13.00 | 10 |
| 15 | 3/7/2012 | 16 | Sam | 13 | 13.00 | 14.5 | 13.00 | 10 |
As I wrap up this post, I have to give a shout out to my daughter, Kristy, who is an honors math student. She helped me get my head around this last group of functions. Her honors math work and some statistical work she had done in science helped provide additional insight into the math behind the functions. (Kristy – you rock!)
Series Wrap Up
I hope this series helps everyone understand the power and flexibility in the window functions made available in SQL Server 2012. If you happen to use Oracle, I know that many of these functions or there equivalent are also available in 11g and they also appear to be in 10g. I have to admit my first real production usage was with Oracle 11g but has since used them with SQL Server 2012. The expanded functionality in SQL Server 2012 is just one more reason to upgrade to the latest version.
![TSQL WIndow Functions_thumb[1]_thumb](https://dataonwheels.files.wordpress.com/2014/07/tsql-window-functions_thumb1_thumb.png "TSQL WIndow Functions_thumb[1]_thumb")
![TSQL WIndow Functions_thumb[1]](https://dataonwheels.files.wordpress.com/2014/06/tsql-window-functions_thumb1.png "TSQL WIndow Functions_thumb[1]")