I am proud to announce the launch of a new book, centered around the importance of SQL, authored by six consultants from 3Cloud. Our new book is called “SQL Query Design Patterns and Best Practices.” This project was brought to us by PACKT and it’s a unique opportunity as we have five brand new authors on the project. Steve Hughes worked with the publisher to create a plan and recruit authors from within the talented data practice at 3Cloud.
The focus of this book is primarily to help those citizen developers who have limited experience in SQL to expand their knowledge to the next level. While the book can be read end to end, it is designed in multiple parts to support different subject areas that meet the needs of these new developers. In the first part of the book, we spend most of our time dealing with best practices on query design. We follow that up with the implementation of some difficult features that have a great use case in report writing and similar types of queries.
The second half of the book guides developers through using query tuning tools and techniques, including indexes. While our focus is not on creating the indexes, it is important to understand how the indexes can impact and improve your queries as you build your queries. We wrap up with some coverage on modern data estate solutions, including working with JSON, querying files, and creating Jupyter notebooks to manage and share SQL solutions.
About the Authors:
This is not the first book that Steve Hughes has worked on, but that is not true for the rest of the authors. Chi Zhang, Leslie Andrews, Dennis Neer, Shabbir Mala, and Ram Babu Singh worked on a few chapters each in this project, which gives them their first opportunity to coauthor a published book. “As lead on this project, I (Steve Hughes) must say I’m very proud that they tackled this project in such a short timeline. I hope this gives them the opportunity to author more books in the future as we look forward to seeing great things from them.”
I am truly excited to have helped 5 new authors get started!
We would like to thank PACKT for their support as we worked through this project. They did a marvelous job supporting this group of new authors on their first project! The project leaders and editors were patient and thoughtful throughout the entire project.
We are all grateful to be working for a company who supports our efforts to become the best consultants in the market and look forward to more opportunities to share our expertise.
If you’re interested in reading the book, please feel free to check us out on Amazon.
This blog is intended to be a follow up from the SQL Saturday 2022 in Oregon & SW Washington. In that session I presented an introduction to FHIR and JSON data produced from the Azure Health Services API’s.
With the recent updated mandates in the healthcare environment in the United States, Microsoft has continued to expand its capability to support the FHIR standard for integrating healthcare data. While the standard is well documented and Microsoft’s capabilities are expansive, it falls on data professionals to interpret that data and build meaningful reports and produce meaningful insights from the data as it is collected and integrated across environments. This requires a good working knowledge of JSON in SQL to manipulate complex data models. In the session, we did a short review of the FHIR standard and the overall implementation of FHIR in Azure. From there we reviewed the resulting data in the data lake and in Synapse. That was followed up with an overview into the heart of complex SQL using JSON functions in Synapse. Whether or not you are active in healthcare today, this will be an enlightening session on how to use JSON SQL functions within the Azure SQL platforms.
What is FHIR and why should you care?
FHIR stands for Fast Healthcare Interoperability Resources. this is the latest specification for interoperability in healthcare produced by HL7. To be clear the word fast has nothing to do with performance, but more about the ability to implement and integrate data quickly. With the latest regulations around the world in health care, this standard is the established standard for integrating healthcare data and we’ll continue to be on the forefront of this work. If you do any work in health care, you will need to understand FHIR because you will likely run across data formatted to the standard from many different sources.
FHIR is very well documented. In many ways when the standard is properly followed the JSON documents or other supported formats are effectively self-documenting. It is commonly understood that the core FHIR specification handles about 80% of the use cases in healthcare. It is designed to be flexible so that it can support specialized needs within regions or healthcare areas. For example, in the US there is a need to support race and ethnicity. The U.S. Core Implementation Guide provides guidance on the specification enhancements to support this need for U.S. healthcare organizations. You will find similar support for other countries as well as specific implementations for healthcare vendors such as Epic.
Neither the notebook, the presentation, or this blog is expected to be and exhaustive coverage of FHIR. before we move on to some of the other implementation pieces, it is important to understand one key aspect of FHIR is the basic building block called a resource. A resource is the core exchangeable content within the specification. All resources share the following characteristics:
A common way to define and represent the resource including data types and patterns
A common set of metadata which can be discovered easily
A human readable part
For more detailed information on the supported resources and other details around FHIR implementation, you should visit the following website:
Azure Health Services and the FHIR API
I will not be digging into a lot of the health care services information nor the FHIR support within Azure in this post. The important things to understand is that Microsoft has made a concerted effort to support this specification which includes technology and architectures for the extraction of data from various healthcare systems which will then use the FHIR APIs to standardize that extracted data into the FHIR spec typically in JSON files in the data lake. Because of the standardized format, Microsoft is able to supply a set of common schemas that can be used in serverless synapse to create external tables and views to accelerate the implementation and usage of data produced from the APIs. It is from this starting point that we are able to start working with the data in reporting and analytics solutions.
At this point I want to put a plug in for the company I work for. If you're interested in learning how Azure health services and the FHIR specification can be implemented at your company, we have FHIR Quick Start and FHIR Data Blueprint solutions. These solutions have been used by many other customers to achieve high levels of integration in their health care data estate. If you're interested in learning more, please reach out to us at: https://3cloudsolutions.com/get-started/
Working with the data from the FHIR API using JSON in SQL
As noted in the previous section, Azure Health Services comes with setup serverless tables and views to be used with the extracted data. However due to the complexity of FHIR, there are a number of columns within those tables and views which still contain JSON snippets. For example, there is one field for name which has several objects and arrays to support the specification. You cannot simply select the name from the table and use that as you move forward. There are many different fields like this throughout the data. For the rest of this blog and in the notebook, we will work through a number of scenarios to build a view of the patient resource that can be used for simple reporting. This view will contain a few JSON functions from SQL Server and solve simple to complex scenarios in the illustration.
The functions we will be using:
ISJSON
JSON_VALUE
OPENJSON
In addition to these functions, we will also be using the CROSS APPLY operator in SQL to join our data with relational data.
The examples in the notebook are built on the tables resulting from working with the Azure FHIR API. I am unable to provide a sample of the data to use with the set of information in the notebook currently. However, the SQL will work if you have your own FHIR implementation and a Patient resource to work with. rather than rewrite the entire contents of the notebook in the blog post, here is a link to the notebook.
If you plan to implement this in the same way, you will need Azure Data Lake, Azure Synapse serverless, and Azure Data Studio. the notebook can be opened in Azure Data Studio. If you are unfamiliar with working with notebooks inside of Azure Data Studio, you are not alone. Check out this post which discusses how to implement your first notebook in Azure Data Studio.
Building our view and SQL with JSON functions
If you decide not to open the notebook but are curious what the view looks like here is a finished product that we created in the notebook.
SELECT TOP (20) p.resourceType + '/' + p.id as PatientResourceID
, p.resourceType as ResourceType
, p.id as ResourceID
, cast(p.[meta.versionId] as int) as VersionID
, cast(p.[meta.lastUpdated] as DATETIME2(7)) as LastUpdated
, JSON_VALUE(p.[name], '$[0].family') as LastName
, JSON_VALUE(p.[name], '$[0].given[0]') as FirstName
, cast(p.active as bit) as IsActive
, p.gender as Gender
, CAST(p.birthDate as date) as BirthDate
, CASE WHEN p.[maritalStatus.coding] is null THEN NULL
WHEN JSON_VALUE(p.[maritalStatus.coding], '$[0].system') = 'http://terminology.hl7.org/CodeSystem/v3-MaritalStatus'
THEN JSON_VALUE(p.[maritalStatus.coding], '$[0].code')
ELSE NULL
END as MaritalStatus
, CASE WHEN JSON_VALUE(p.[address], '$[0].use') = 'home' THEN JSON_VALUE(p.[address], '$[0].state')
WHEN JSON_VALUE(p.[address], '$[1].use') = 'home' THEN JSON_VALUE(p.[address], '$[1].state')
WHEN JSON_VALUE(p.[address], '$[2].use') = 'home' THEN JSON_VALUE(p.[address], '$[2].state')
WHEN JSON_VALUE(p.[address], '$[3].use') = 'home' THEN JSON_VALUE(p.[address], '$[3].state')
ELSE NULL
END as HomeStateOrProvince
, e.Ethnicity
, r.Race
FROM fhir.Patient p
INNER JOIN (SELECT id, max([meta.versionId]) as currentVersion FROM fhir.Patient GROUP BY id) cp
ON p.[meta.versionId] = cp.currentVersion
AND p.id = cp.id
LEFT JOIN
(SELECT p.id
, CASE WHEN JSON_VALUE(ext.value,'$.extension[0].url') = 'ombCategory'
THEN
CASE WHEN JSON_VALUE(ext.value, '$.extension[1].valueString') IS NOT NULL THEN JSON_VALUE(ext.value, '$.extension[1].valueString')
WHEN JSON_VALUE(ext.value, '$.extension[0].valueString') IS NOT NULL THEN JSON_VALUE(ext.value, '$.extension[0].valueString')
ELSE JSON_VALUE(ext.value, '$.extension[0].valueCoding.display')
END
ELSE JSON_VALUE(ext.value, '$.valueCodeableConcept.coding[0].display')
END AS Ethnicity
FROM
(
SELECT fp.id, fp.extension FROM fhir.Patient fp
INNER JOIN (SELECT id, max([meta.versionId]) as currentVersion FROM fhir.Patient GROUP BY id) cp
ON fp.[meta.versionId] = cp.currentVersion
AND fp.id = cp.id
WHERE ISJSON(fp.extension) =1
) p
CROSS APPLY
OPENJSON(p.extension,'$'
) as ext
WHERE JSON_VALUE(ext.value,'$.url') = 'http://hl7.org/fhir/us/core/StructureDefinition/us-core-ethnicity'
) e on e.id = p.id
LEFT JOIN
(SELECT p.id
, CASE WHEN JSON_VALUE(ext.value,'$.extension[0].url') = 'ombCategory'
THEN
CASE WHEN JSON_VALUE(ext.value, '$.extension[3].valueString') IS NOT NULL THEN JSON_VALUE(ext.value, '$.extension[3].valueString')
WHEN JSON_VALUE(ext.value, '$.extension[2].valueString') IS NOT NULL THEN JSON_VALUE(ext.value, '$.extension[2].valueString')
WHEN JSON_VALUE(ext.value, '$.extension[1].valueString') IS NOT NULL THEN JSON_VALUE(ext.value, '$.extension[1].valueString')
WHEN JSON_VALUE(ext.value, '$.extension[0].valueString') IS NOT NULL THEN JSON_VALUE(ext.value, '$.extension[0].valueString')
ELSE JSON_VALUE(ext.value, '$.extension[0].valueCoding.display')
END
ELSE JSON_VALUE(ext.value, '$.valueCodeableConcept.coding[0].display')
END AS Race
FROM
(
SELECT fp.id, fp.extension FROM fhir.Patient fp
INNER JOIN (SELECT id, max([meta.versionId]) as currentVersion FROM fhir.Patient GROUP BY id) cp
ON fp.[meta.versionId] = cp.currentVersion
AND fp.id = cp.id
WHERE ISJSON(fp.extension) =1
) p
CROSS APPLY
OPENJSON(p.extension,'$'
) as ext
WHERE JSON_VALUE(ext.value,'$.url') = 'http://hl7.org/fhir/us/core/StructureDefinition/us-core-race'
) as r on r.id = p.id
Here is a sample of the results from that view:
PatientResourceID
ResourceType
ResourceID
VersionID
LastUpdated
LastName
FirstName
IsActive
Gender
BirthDate
MaritalStatus
HomeStateOrProvince
Ethnicity
Race
Patient/d8af7bfa-5008-4a0f-85d1-0af3448a31dd
Patient
d8af7bfa-5008-4a0f-85d1-0af3448a31dd
2
2022-05-31 18:07:03.2150000
DUCK
DONALD
1
male
1965-07-14
NULL
ON
NULL
NULL
Patient/78cf7725-a0e1-44a4-94d4-055482781afb
Patient
78cf7725-a0e1-44a4-94d4-055482781afb
1
2022-05-31 18:07:30.7490000
Gretzky
Wayne
NULL
NULL
1990-05-31
NULL
NULL
NULL
NULL
Patient/9e909e52-61a1-be50-1878-a12ef8c36346
Patient
9e909e52-61a1-be50-1878-a12ef8c36346
4
2022-05-31 18:39:58.1780000
EVERYMAN
ADAM
NULL
male
1988-08-18
M
NULL
Non Hispanic or Latino
White+Asian
Patient/585f3cc0-c727-4989-9214-a7a7b60a2ade
Patient
585f3cc0-c727-4989-9214-a7a7b60a2ade
1
2022-05-31 13:14:57.0640000
DUCK
DONALD
1
male
1965-07-15
NULL
ON
NULL
NULL
Patient/29a819c4-f553-8189-2354-9441b86d37ef
Patient
29a819c4-f553-8189-2354-9441b86d37ef
1
2022-05-18 15:18:40.1560000
FORD
ELAINE
NULL
female
1992-03-10
NULL
NULL
NULL
NULL
Patient/d5fe6802-a680-e762-8f43-9659340b00ac
Patient
d5fe6802-a680-e762-8f43-9659340b00ac
3
2022-05-18 14:39:52.2550000
EVERYMAN
ADAM
NULL
male
1961-06-15
S
NULL
NULL
C
Patient/4d661053-a8d0-148c-7023-54508fd04a52
Patient
4d661053-a8d0-148c-7023-54508fd04a52
1
2022-05-21 13:48:24.9720000
EVERYMAN
sam
NULL
male
1966-05-07
M
NULL
Not Hispanic or Latino
White
Wrapping it up
As you can see, understanding the specification well enough to build a complex SQL statement using JSON functions is required to work within FHIR effectively. Due to the complex nature of the nested JSON, you may not be able to reconcile this in tools such as power BI. Being able to build this out in SQL guarantees that you have provided you will report writers and analysts with a solid result set which can be used with confidence.
This blog covers the content and points to the code used to create the demos in my Azure SQL Database Elasticity presentations. As of today, I have presented this at the Minnesota SQL Server User Group (PASSMN) in September 2020 and as a webinar for 3Cloud in October 2020.
Elastic Queries
Elastic queries allow developers to interact with data from multiple databases supported on the Azure SQL database platform including Synapse. Elastic queries are often referred to as Polybase which is currently implemented in SQL Server 2019 and Azure Synapse. The key difference is that elastic queries only allow you to interact with other Azure SQL Databases but not Hadoop or other database implementations (e.g. Teradata or Oracle). Part of the confusion comes from the fact that the implementation looks very similar. Both toolsets use external tables in SQL Server to interact with the connected data sources. However, Polybase requires additional components to run whereas elastic queries are ready to go without additional setup.
Be aware elastic queries are still in preview. Also, elastic queries are included in the cost of Azure SQL Database in standard and premium tiers.
Elastic Query Strategies
Elastic queries support three key concepts and will influence how you implement the feature.
Vertical partitioning. This concept uses complete tables in separate databases. It could be a shared date table or dimensions in a data warehouse solution. Vertical partitioning is a method to scale out data solutions. This is one method to use Azure SQL database for larger data solutions.
Horizontal partitioning or sharding. Whereas vertical partitioning keeps tables together, horizontal partitioning shards or spreads the data from a single table across multiple Azure SQL Databases. This is the most complex type of partitioning as it requires a shard map. This is typically implemented with .NET or Java applications.
Data virtualization. This concept is a mix of the partitioning solutions to achieve the goal of virtualizing the data. The idea with data virtualization is that we can use a single Azure SQL Database to interact with data from multiple databases. While this concept is limited due to the limit to use Azure SQL Databases, it is a concept to look for more improvements as the product matures even more.
Elastic Query Demo
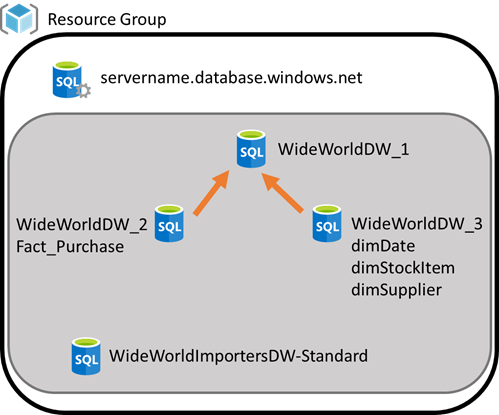
The demo used in the presentations is configured as shown here:
Three S1 Azure SQL Databases on the same Azure SQL Server. I used ADF (Azure Data Factory) to move Fact.Purchase to WideWorldDW_2 and the three related dimensions (dimDate, dimStockItem, dimSupplier) to WideWorldDW_3. I then used WideWorldDW_3 to implement the external tables to work with the data. The WideWorldImportersDW-Standard was used as the original restore of the sample database. It is the source of the data but is not used in the demos.
One note on the demo. I did not include the ADF jobs. Use the Copy activity to move the tables to the target databases. You can find more information here.
The demo code to set up the environment can be found here.
Elastic Jobs
Elastic jobs is the alternative to SQL Server Agent Jobs in Azure SQL Database. While Agent is included in Azure SQL Managed Instance, the rest of the platform needed an option to create jobs. Elastic jobs solves that issue. Currently this is also in preview and is also included with Azure SQL Database. The only additional cost is that a dedicated job database is required to support elastic jobs.
The best comparison is still with SQL Server Agent. Elastic jobs are structured with jobs which have job steps. The only limitation at the moment is that job steps must be T-SQL. Jobs can be created in the Azure portal, with PowerShell, with REST, or with T-SQL.
Elastic Transactions
One of the key pieces that was originally missing from the Azure SQL Database rollout was cross database transactions that were supported in SQL Server with MSDTC. Elastic transactions add this functionality to Azure SQL Database and is built into the platform. This functionality is application driven and currently supported in the latest .NET libraries. Overall, this will allow you to support transactions across 100 databases or fewer. While there is no limit, Microsoft currently recommends only using this to support distributed transactions over 100 or less databases due to potential performance issues.
There are a few limitations to be aware of:
Only supports Azure SQL Databases
Only supports .NET transactions
Does not support T-SQL Distributed transactions
Does not support WCF transactions
Wrap Up
Microsoft continues to improve the functionality in Azure SQL Database. These elastic features are part of that process. While I typically do not have many uses for distributed transactions, we have actively implemented elastic queries and elastic jobs for customers and look to use them more in the future.
A problem that has plagued SQL developers through the years is splitting strings. Many techniques have been used as more capabilities were added to SQL Server including XML datatypes, recursive CTEs and even CLR. I have used XML datatype methods to solve the problem most often. So, without further ado…
T-SQL Function: STRING_SPLIT
I have previously highlighted this function in a webinar with Pragmatic Works as a Hidden Gem in SQL Server 2016. It was not announced with great fanfare, but once discovered, solves a very common problem.
Syntax
STRING_SPLIT(string, delimiter)
The STRING_SPLIT function will return a single column result set. The column name is “value”. The datatype will be NVARCHAR for strings that are NCHAR or NVARCHAR. VARCHAR is used for strings that are CHAR or VARCHAR types.
Example
DECLARE @csvString ASVARCHAR(100)
SET @csvString = 'Monday, Tuesday, Wednesday, Thursday, Friday'
SELECTvalue AS WorkDayOfTheWeek
FROMSTRING_SPLIT (@csvString, ',');
The initial example returns the follow results:#tsql2sday
value
Monday
Tuesday
Wednesday
Thursday
Friday
As you can see in the example, the results returned a leading space which was in the original string. The following example trims leading and trailing spaces.
DECLARE @csvString ASVARCHAR(100)
SET @csvString = 'Monday, Tuesday, Wednesday, Thursday, Friday'
SELECTLTRIM(RTRIM(value)) AS WorkDayOfTheWeek
FROMSTRING_SPLIT (@csvString, ',');
The cleaned example returns the follow results:
value
Monday
Tuesday
Wednesday
Thursday
Friday
Thanks again Matt for this opportunity to share an underrated, but really useful shiny new tool in SQL Server 2016.
Thanks for attending my session on window functions in TSQL. I hope you learned something you can take back and use in your projects or at your work. You will find an link to the session and code I used below. If you have any questions about the session post them in comments and I will try to get you the answers.
Questions and Comments
Does RATIO_TO_REPORT exist in SQL Server? It is in Oracle.
Currently this function is not available in SQL Server
Here is the equivalent functionality using existing functions in SQL Server:
OrderAmt / SUM(OrderAmt) OVER (PARTITION BY OrderDate)
This example can use the source code I have referenced below. It uses the current value as the numerator and the sum by partition as the denominator. While not a simple function, the equivalent is still fairly simple using window functions to help.
Demo issues with Azure SQL Database
During the session I ran into an issue with Azure SQL Database. It turns out that the following two functions are not supported there.