
Had an absolutely amazing time at SQLBits this year! It was lovely to see all my data friends again and had the opportunity to introduce my husband to everyone as well! In case you missed a session, or are curious about what I learn at these conferences, below are my notes from the various sessions I attended.
Here is a link to my GitHub that contains the slides and code from my presentation on creating a M-agical Date Table. Thank you to everyone who attended! https://github.com/Anytsirk12/DataOnWheels/tree/main/SQLBits%202024
What’s new in Power Query in Power BI, Fabric and Excel? by Chris Webb
Power query online is coming to PBI desktop and will include diagram & schema views, the query plan, and step folding indicators! Currently in private preview, coming to public preview later this year.
Power query in Excel. Nested data types now work (very cool, check this out if you don’t know what data types are in Excel). Python in excel can reference power query queries now which means we don’t have to load data into Excel! That will allow analysis of even more data because you can transform it upstream of the worksheet itself. Very cool.
Example: import seaborn as sns
mysales = xl(“Sales”)
sns.barplot(mysales, x=”Product”, y = “sales”, ci=None)
Limitations – can’t use data in the current worksheet.
Power query is in Excel online! Later this year, you will be able to connect to data sources that require authentication (like SQL Server!).
Power query can be exported as a template! This will create a .pqt (power query template). You can’t import a template file in Excel, but you can in Dataflows Gen2 in Fabric.
Fabric Dataflow Gen2 – data is not stored in the dataflow itself. We now have Power Query copilot! It’s in preview, but it’s coming. You will need a F64 to use it.
Paginated reports are getting power query!! It will be released to public preview very soon. All data sources will be available that are in power bi power query. This will allow snowflake and big query connections annnddd excel! You can even pass parameters to the power query get data by creating parameters within the power query editor. Then you go to the paginated report parameters and create the parameter there. Finally go to dataset properties and add a parameter statement that sets those two equal to each other.
Rapid PBI Dev with ChatGPT, Tips & Tricks by Pedro Reis
Scenario 1: DAX with SVG & CSS.
SVG – Problem is to create a SVG that can have conditional formatting that doesn’t fill the entire cell. ChatGPT does best with some working code, so give it a sample of the SVG you want and as ChatGPT to make it dynamic. Demo uses GPT4 so we can include images if needed. He uses Kerry’s repo to get the code sample that we put into GPT (KerryKolosko.com/portfolio/progress-callout/).
CSS – uses HTML Content (lite) visual (it’s a certified visual). Prompt asks gpt to update the measure to increase and decrease the size of the visual every 2 seconds. Pretty awesome looking. He’s also asking it to move certain directions for certain soccer players (Ronaldo right and Neymar zigzag).
Scenario 2: Data Modeling and analysis. He uses Vertabelo to visualize a datamodel and it creates a SQL script to generate the model. He passes the screenshot of the datamodel schema to ChatGPT and it was able to identify that a PK was missing and a data type was incorrect (int for company name instead of varchar). Super neat. The image does need to be a good resolution. He also put data from excel into GPT to have it identify issues like blanks and data quality issues (mismatched data types in the same column). It could grab invalid entries and some outliers but it’s not very reliable now.
Scenario 3: Report Design Assessment. He grabbed four screenshots from a Power BI challenge and asked GPT to judge the submissions with a 1-10 rating based on the screenshots and create the criterion to evaluate the reports. Very neat! Then he asked it to suggest improvements. It wasn’t very specific at first so he asked for specfic items like alternatives to donut charts and other issues that lowered the score.
Scenario 4: troubleshooting. He asks it to act as a power bi expert. It was able to take questions he found on the forum, but sometimes it hallucinate some answers and it’s not trained on visual calculations yet.
Scenario 5: Knowledge improvement. He asked GPT to create questions to test his knowledge of Power BI models. It even confirmed what the correct answers. It even created a word doc for a shareable document that can be used to test others in the future.
Streamlining Power BI with Powershell by Sander Stad and Linda Torrang
Data-Masterminds/PSPowerBITools is an open source code that is in the powershell gallery as well as within GitHub. Github link: https://github.com/Data-Masterminds/PSPowerBITools.
There’s a module called MIcrosoftPowerBIMgmt that is used with a service account to wrap around the rest api and allow easier calls of those APIs through powershell. When running PowerShell, to see the things in a grid use the code ” | Out-GridView” at the end of your command and it creates a very nice view of the data. All demos are available at github. The first demo is to grab all the orphaned workspaces then assign an admin. Their module includes more information like the number of users, reports, datasets, etc. They also have a much easier module that will grab all the activity events from a given number of days (it will handle the loop for you).
Another great use case will be moving workspaces from a P SKU capacity to a F SKU capacity automatically. The admin management module doesn’t work for this, but the PSPowerBITools module can! To see help – use “get-help” in front of the command to get details and examples. For more details, add “-Detailed” at the end to see that. Adding “-ShowWindow” at the end of a script will pop open a separate window to see the response (note- doesn’t work with -Detailed but does contain the details). To export use this script: $workspaces | Export-Csv -NoVolbber -NoTypeInformation -Path C:\Temp\export_workspaces.csv.
The goal is to use the module for more ad hoc admin tasks like remove unused reports, personal workspaces, data sources, and licenses.
New to Powershell like me? Check out this article on how to automate Powershell scripts to run on your laptop: https://www.technewstoday.com/how-to-automate-powershell-scripts/.
Using ALLEXCEPT or ALL-VALUES by Marco Russo
ALL: removes all the filters from expanded table/columns specified.
REMOVEFILTERS: like ALL (it’s the same function). We use this for code readability.
ALLEXCEPT: removes filters from expanded table in the first argument, keeping the filter in the following table/columns arguments.
The following produce the same result:
ALLEXCEPT(customer, customer[state], customer[country])
REMOVEFILTERS(customer[customerkey], customer[name], customer[city])
The nice thing about ALLEXCEPT is that it’s future proof against additional fields being added to the table.
But is it the correct tool?
Demo – goal is to get % of continent sales by getting country or state or city sales / total continent sales
To get that total continent sales, we need sales amount in a different filter context. The simplest way to do this is using ALLEXCEPT since we always only want the continent field from the customer table.
CALCULATE([Sales Amount], ALLEXCEPT( customer, customer[continent]))
This works if we include fields from the same table – customer. If we pull in fields from another table, it won’t work as we want because it will be filtered by a different table’s filter context. To get rid of that, you can add REMOVEFILTERS(‘table’) for each OR we can change the ALLEXPECT to use the fact table.
CALCULATE([Sales Amount], ALLEXCEPT( Sales, customer[continent]))
One problem is if a user drops the continent from the visual, the filter context no longer includes continent so the ALLEXCEPT will no longer work properly as it will function as an ALL.
To fix this, use remove filters and values. Using values adds in the continent value in the current filter context, then removes the filter context on customer. Lastly, it applies the value back into the filter context so we end up with what we want which is just continent is filtered. This works quickly because we know each country will only have one continent.
CALCULATE( [sales amount], REMOVEFILTERS( Customer, VALUES (customer[continent]))
Performance difference? Yes – ALLEXCEPT will be faster, but the REMOVEFILTERS and VALUES should not be too much slower.
Analytics at the speed of direct lake by Phillip Seamark and Patrick LeBlanc
Phil did a 100 minute version of this session on Wednesday.
What is direct lake? We will evaluate over three categories – time to import data, model size, and query speed. Direct lake mode takes care of the bad things from both import and direct query modes. Direct lake only works with one data source. Data is paged into the semantic model on demand triggered by query. Tables can have resident and non-resident columns. Column data can get evicted for many reasons. Direct Lake fallback to SQL server for suitable sub-queries. “Framing” for data consistency in Power BI reports. Direct lake model starts life with no data in memory. Data is only pulled in as triggered by the DAX query. Data stays in that model once pulled for hours. We only grab the columns we need which saves a ton of memory.
Limitations – no calculated columns or tables. No composite models. Calc groups & field parameters are allowed. Can’t be used with views, can only be used with security defined in the semantic model (you can have RLS on the semantic model itself). Not all data types are supported. If any of these are true, Power BI will fall back to Direct Query mode.
SKU requirements: only PBI premium P and F skus. No PPU nor pro license.
Why parquet? column-oriented format is optimised for data storage and retrieval. Efficient data compression and encoding for data in bulk. Parquet is also available in languages including rust, java, c++, python, etc. Is lingua franca for data storage format. Enhanced with v-order inside of Fabric which gives you extra compression. Analysis services can read and even prefers that form of compression so we don’t need to burn compute on the compression. V-Order is still within open source standards so this still doesn’t lock you into Fabric only. Microsoft has been working on V-Order since 2009 as part of Analysis services. Row group within parquet files corresponds directly to the partitions/segments in a semantic model. Power BI only keeps one dictionary, but parquet has a different dictionary id for each row group/partition. When calling direct query, low cardinality is key because most of the compute will go to the dictionary values that need to be called across the various partitions. This is why it’s VITAL to only keep data you need for example, drop or separate times from date times and limit decimals to 2 places whenever possible.
You can only use a warehouse OR a data lake. So if you need tables from both, make a shortcut from the data lake to the warehouse and just use the warehouse. You can only create a direct lake model in the online service model viewer or in Tabular editor. You cannot create it in PBI desktop today.
Microsoft data demo. One file was 880 GB in CSV > 268 GB in Parquet > 84 GB with Parquet with V-ORDER.
Sempty is a python library that allows you to interact with semantic models in python.
In the demo, Phil is using sempty and semantic-link libraries. Lots of advantages to using the online service for building the semantic model – no loading of data onto our machines which makes authoring much faster. After building this, you can run a DMV in DAX studio. Next, create a measure/visual that has a simple max of a column. That will create a query plane to reach out to parquet and get the entire column of data needed for that action then filter as needed. After that, the column will now be in memory. Unlike direct query, direct lake will load data into model and keep it for a bit until eviction. The direct lake will also evict pages of columns as needed when running other fields. You can run DAX queries against the model using python notebook and you can see via DMV what happened.
Framing. Framing is a point in time way of tracking what data can be queried by direct lake. Why is this important? data consistency for PBI reports, delta-lake data is transient for many reasons. ETL Process – ingest data to delta lake tables. What this does is creates one version of truth of the data at that point of time. You can do time traveling because of this, but keep in mind that for default models it frames pretty regularly. If you have a big important report to manage, you need to make sure to include reframing in the ETL process so it reloads the data properly. This can be triggered via notebook, service, api, etc. You can also do this in TMSL via SSMS which gives you more granular table control.
DAX to SQL Fallback. Each capacity has guard rails around it. if you have more than a certain number of rows in a table, then it will fall back to direct query automatically. Optimization of parquet files will be key to stop it from falling back.
Deep (Sky)diving into Data Factory in Microsoft Fabric by Jeroen Luitwieler
Data Pipeline Performance – How to copy scales.
Pipeline processing – less memory & less total duration. No need to load everything into memory then right. Read and Write are done in parallel.
Producer and consumer design. Data is partitioned for multiple concurrent connections (even for single large files). Full node utlization. Data can be partitioned differently between source and sink to avoid any starving/idle connections.
Partitions come from a variety of sources including physical partitions on the DB side, dynamic partitions from different queries, multiple files, and multiple parts from a single file.
Copy Parallelism concepts: ITO (Intelligent Throughput Optimization), Parallel copy, max concurrent connections. ITO – A measure that represents the power used which is a combo of CPU, memory, and network resource allocation used for a single copy activity. Parallel copy – max number of threads within the copy activity that read from source and write to sink in parallel. Max concurrent connections – the upper limit of concurrent connections established to the data store during the activity run (helps avoid throttling).
Metadata-driven copy activity. Build large-scale copy pipelines with metadata-driven approach in copy inside Fabric Data pipeline. You can’t parameterize pipelines yet, but it is coming. Use case is to copy data from multiple SQL tables and land as CSV files in Fabric. Control Table will have the name of the objects (database, schema, table name, destination file name, etc). Design has a lookup to get this control table and pass that through a foreach loop and iterate through these to copy the tables into Fabric.
Dataflows Gen2 – performance optimization and AI infused experiences. 4 performance principles – delegate to the most capable resource, sometimes you have to do the most expensive thing first, divide and conquer, be lazy do as little work as possible.

Query folding – known as query delegation, push down, remote/distributed query evaluation. Wherever possible, the script in Power Query Editor should be translated to a native query. The native query is then executed by the underlying data source.
Staging – load data into Fabric storage (staging lakehouse) as a first step. The staged data can be referenced by downstream queries that benefit from SQL compute over the staged data. The staging data is referenced using the SQL endpoint on the lakehouse. Staging tips – data sources without query folding like files are great candidates for staging. For faster authoring, have a different dataflow for staging and another for a transformations.
Partitioning – a way to break down a big query into smaller pieces and run in parallel. Fast copy does this in the background.
Lazy evaluation – power query only evaluates and executes the necessary steps to get the final output. It checks step dependencies then applies query optimization to make the query as efficient as possible.
AI infused experiences – column by example, table by example, fuzzy merge, data profiling, column pair suggestions. Table by example web is pretty awesome. You can extract any data from any HTML page and have it figure out how to turn that HTML into the table you want to see. Basically allows you to screenscrape as part of your ETL process and it will refresh if any changes are done on the website. Table by example for a text/csv is also amazing, it can try to figure out how to take a human readable file and split it into multiple columns. Game changers!
Website Analytics in my pocket using Microsoft Fabric by Catherine Wilhelmsen
Catherine built her own website and blog hosted on Cloudflare. Cloudflare has an API that pulls all the stats. To build this, she worked with Cloudflare GraphQL API. They have one single endpoint for all API calls and queries are passed using a JSON object.
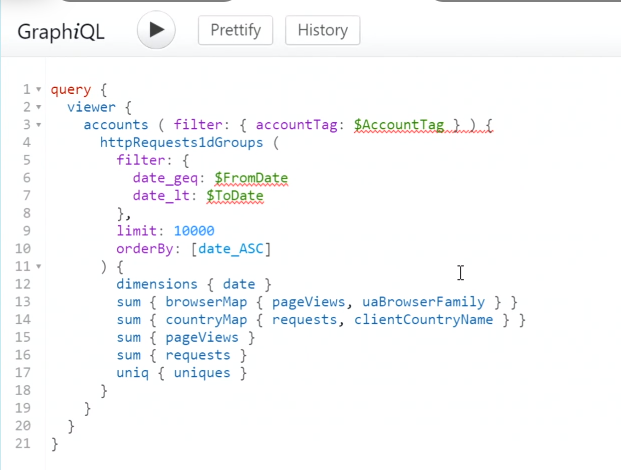
Data is returned as a json object. She built the orchestration inside of Fabric Data Factory.
First portion is to set the date, she has this check if she wants to use today’s date or the custom date.

After that, she accesses the data using a copy data activity. Last step is to copy that data into a lakehouse. The file name is dynamic so she can capture the date that the data was pulled from.
The destination is a Lakehouse where she can build a report off of it. The best part of the copy data is the ability to map that nested JSON response into destination columns within the lakehouse. As a bonus for herself, she made a mobile layout so she can open it on her phone and keep track of it on the go.
Next steps for her project – see country statistics, rank content by popularity, compare statistics across time periods.
Calculation Groups & C# the perfect couple by Paulina Jedrzejewska
Love story between calculation groups and C#.
All slides are available on her github: https://github.com/pjedrzejewska
What makes it a perfect couple? We can add C# to our calc group dev to make it much more flexible.
Calc groups don’t allow you to create a table with customizable sorting of the measures and have measures not using the calc group within the same visual. For example, if I have previous year and current year in my calc group, it would display all of my current year measures together and all the prior year measures together, but I may want to see current year sales right next to prior year sales instead of having current year sales, revenue, cost, etc. then have the prior year much further away. To solve this, we will create separate measures for each time intelligence option. But why do that by hand when we can automate?
What can we automate? Creating & deleting measures, renaming objects, moving objects to folders, formatting objects.
Why automate? Works through a bunch of objects in seconds, reusable, homogeneous structure and naming, and no more tedious tasks for you!
For this demo, we will use Tabular Editor 2, PBI Desktop, Code Editor (visual studio code). She uses a .cs file to script out the code. All the columns in the fact table that will be turned into a measure have a prefix of “KPI”.
column.DaxObjectFullName will give you the full table, column reference which allows you to reference that dynamically within C# code.
Calculation groups are essentially a template for your measures. It’s a feature in data modeling that allows you to take a calculation item and use it across multiple measures. These are very useful for time intelligence, currency conversion, dynamic measure formatting, and dynamic aggregations.
When creating a calc group, always be sure to include one for the actual measure value by using SELECTEDMEASURE(). You can also refer to other calculation items within others as a filter.
Now that we have a calc group, the C# can loop through every base measure and through all the calculation group items and generate our new measures off of that. Remember all the code is in her github 🙂
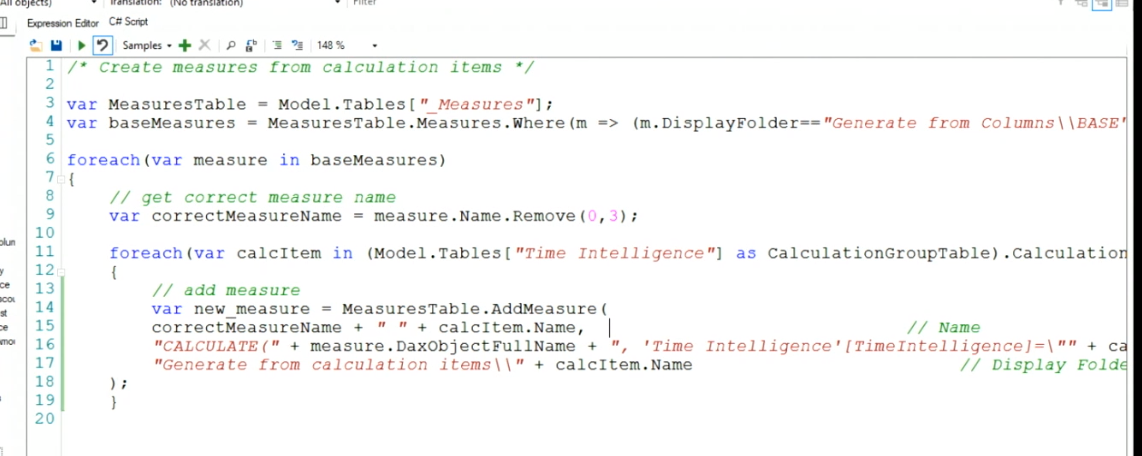
Another great use case for C# is to add descriptions to all the measures.
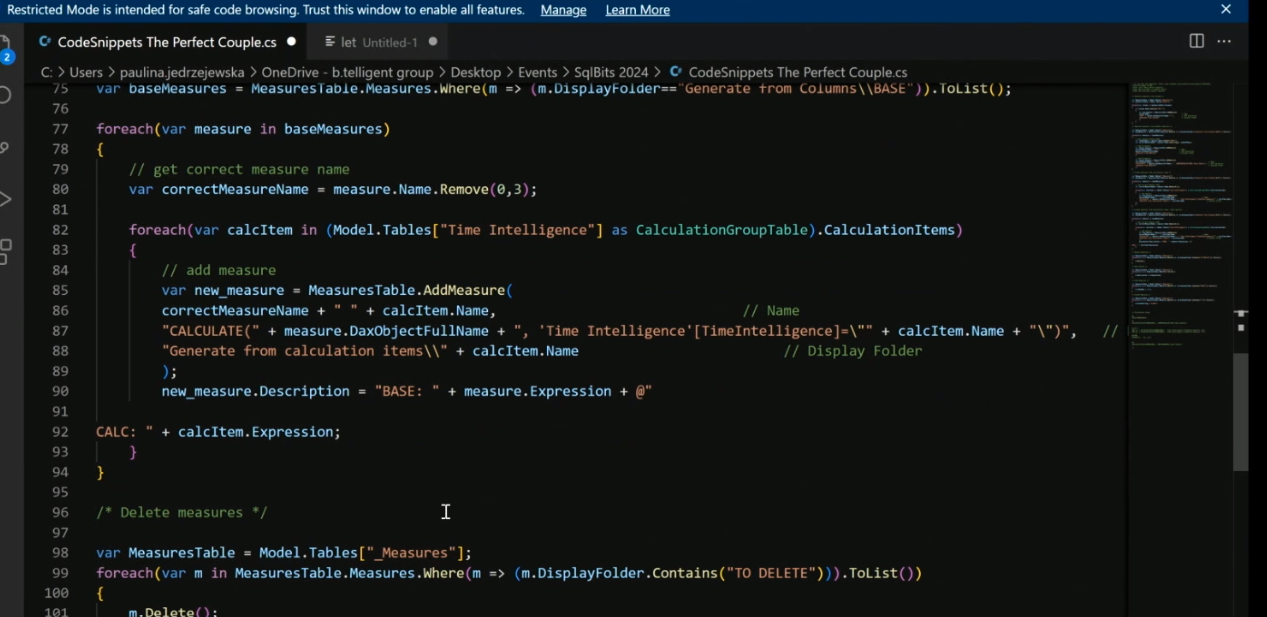
This allows for self-documented code.


























